- Published on
The knowledge gravity problem
- Authors
- Name
- Damian Płaza
- @raimeyuu


I hugely recommend reading Balancing Coupling by Vlad Khononov, it's worth reading and tinkering!
Total innovation!
This is Tom (you might recognize him from The ambiguity, the curse and the fallacy of domain model or from Many Faces of DDD Aggregates in F#).
He is a business owner and really likes helping people.
He came to us to get some help with his new idea.

Hi! I'm Tom and I have a great idea to start up a new initiative.
It's about gathering specialists and allowing them to share their knowledge.
Do you think we can build it?
That's really intersting, Tom!
It's great that we learned Domain-Driven Design and we can apply the knowledge.
To express the domain language, also known as Ubiquitous Language, let's capture important entities like GroupChat and Member.
public class GroupChat
{
public string Topic { get; init; }
public List<Member> Members { get; init; }
}
public class Member
{
public MemberProfile Profile { get; init; }
public bool IsAccepted { get; init; }
}
public class MemberProfile
{
public Guid Id { get; init; }
public string Name { get; init; }
public string Expertise { get; init; }
}
Let's check with Tom if we understood him correctly.
But before that, one should not forget that many people interested in Domain-Driven Design (DDD) say that rules are a very important concept in DDD - much more important than just entities.
If you recall dear Reader, in Many Faces of DDD Aggregates in F# we tried to think about rules (also known as invariants) and make them always "valid".
Should we do the same here?
Rules? Yes, of course!
Finally, rules, hence some operations that need to be performed on our entities!
public class GroupChat
{
public string Topic { get; init; }
public List<Member> Members { get; init; }
public void AddMember(Member member)
{
if (Members.Count < 1000 && !Members.Contains(member)) // 👈 protecting invariants!
{
Members.Add(member);
member.Accept(); // 👈 we've added domain-sounding method!
}
}
}
Seems like GroupChat is a good candidate for an DDD aggregate, isn't it?
public class GroupChat : AggregateRoot<GroupChatId> // 👈 must-have in a real DDD project!
Ok, this looks good.
Change, change never changes
Imagine we got a quick chat (pun intended) with Tom and he told us that he wants to put a name on the GroupChat.
Fair enough. It's a simple change.
"Name quickly, rename even quicker", as they say, right?
So let's add a possibility to rename a GroupChat.
We know that Tom did not asked about it, but it's not the first system we built, and we know those business folks.
public class GroupChat: AggregateRoot<GroupChatId>
{
public string Topic { get; init; }
public string Name { get; init; } // 👈 new property!
public List<Member> Members { get; init; }
public void Rename(string newName, Member renamingMember)
{
if(renamingMember.CanRenameGroupChat(Id)) { // 👈 check if member can rename the group chat
Name = newName;
}
throw Domain.Error("Group chat cannot be renamed by this member.");
}
}
Yeah, as we (speculatively) added a new behavior, we also needed to adjust Member to include information related to permissions.
We also heard that there's an idea to let members establish nicknames for themselves in the GroupChat.
But let's wait with implementing that.
Retrospection!
Now, let's take a step back and look at what we have.
What do you think about this design, dear Reader?
I really hope you feel and see that I am exaggerating a bit, as no one creates such domain models, right?
We typically think about how concepts are going to be used, what are the conditions and contexts those concepts are operating in, isn't it?
If we followed this design, we might eventually fall into the trap related to The ambiguity, the curse and the fallacy of domain model.
We would try to build up a compile-time, absolute-based, reality-chasing model - as we hear the language while talking with the "business people".
Knowledge attracts knowledge?
But it seems that there's an interesting phenomenon happening.
Imagine that we have a problem space - let's represent it like this:

As Tom named the concept living in this particular problem space, a boundary got established.
We could call it "a knowledge boundary" (you can read more about this topic by reading Balancing Coupling).
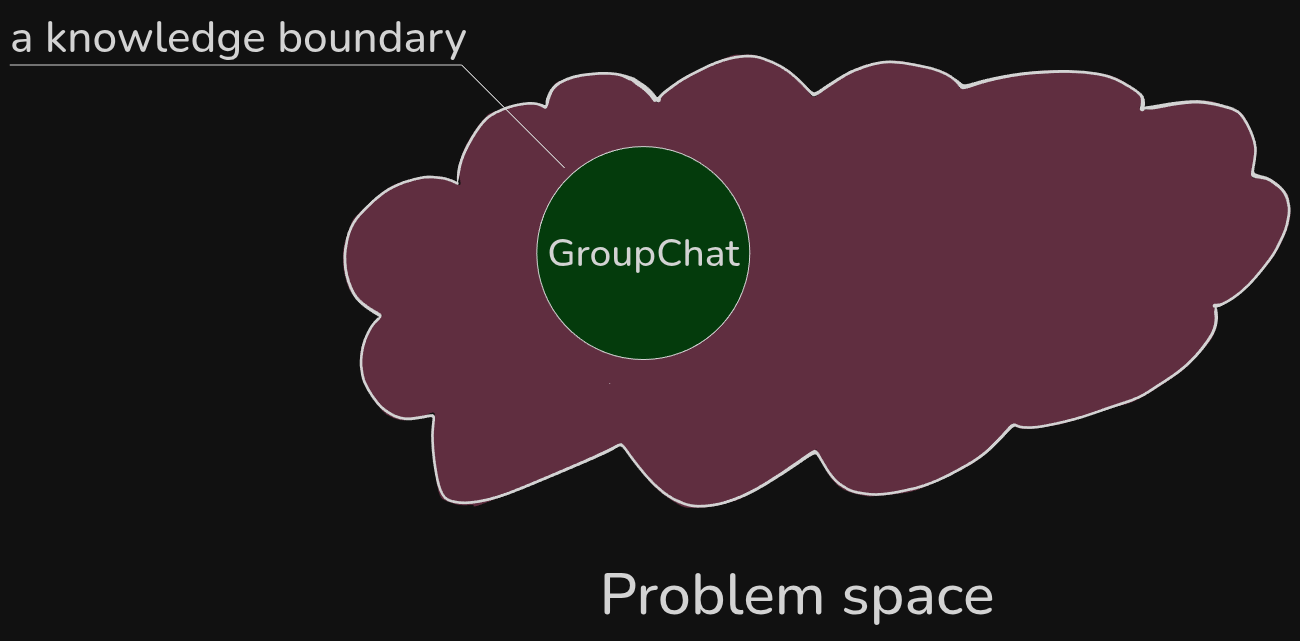
By directly following the language, we could say that we brought a named space into existence.
The more we explore, the time flies by, and more and more concepts are appearing in this space.
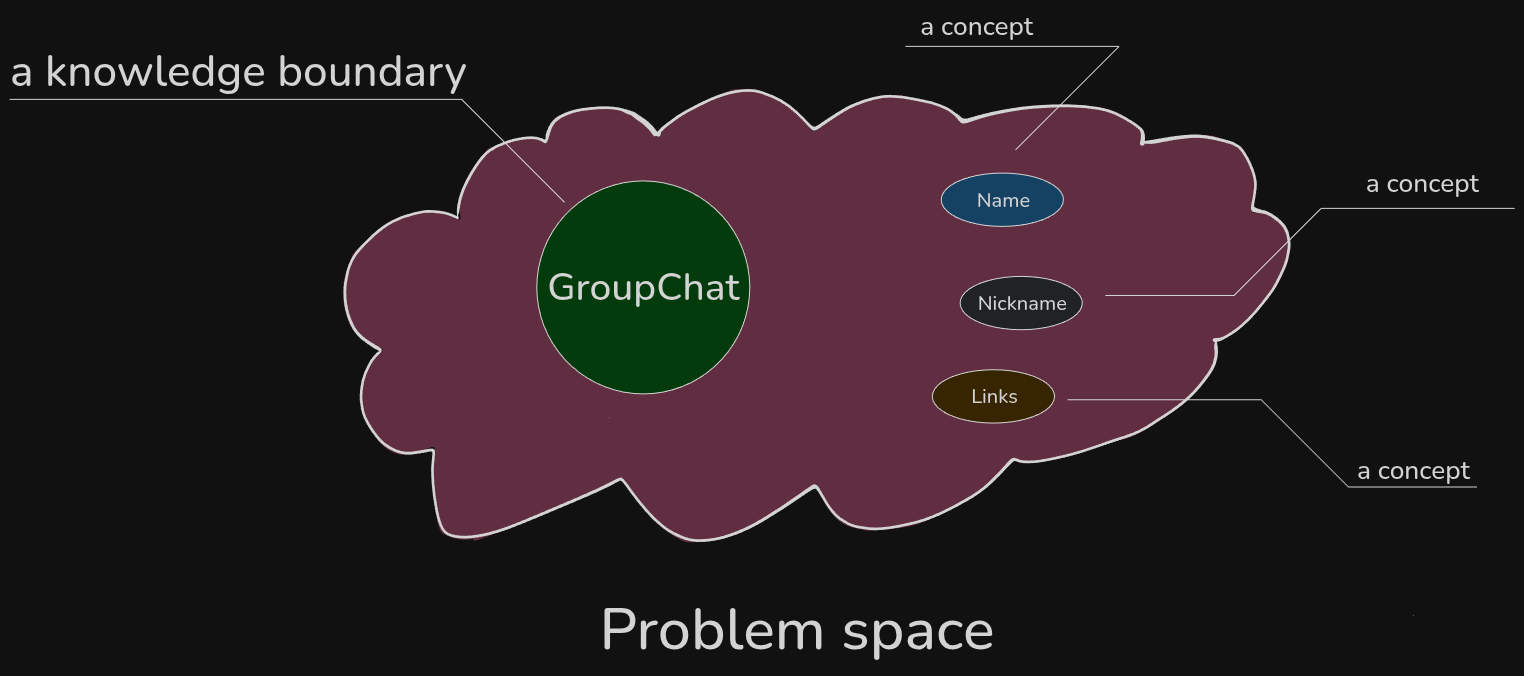
In our tiny exercise, when a Name concept appeared (and he speculatively added "renaming" behavior), didn't it seem almost "natural" to integrate it into the GroupChat?
As if GroupChat was attracting this concept, as it seemed conceptually "close" to it.
We could start reasoning: the knowledge boundary that got framed by GroupChat concept is attracting concepts with varying force.
Some words feel more conceptually close to GroupChat (or Member, which is conceptually close to GroupChat), while others are more "distant" (or different).
This seems like a very subtle process, especially when the existing "structure" (here: compile-time hierarchies, the domain model) is rigid and pushes back (resists) doing changes in an agile and swift manner.
And of course there's a time pressure, deadlines, no time for "refactoring", and so on.
So those structures accomodate more and more knowledge.
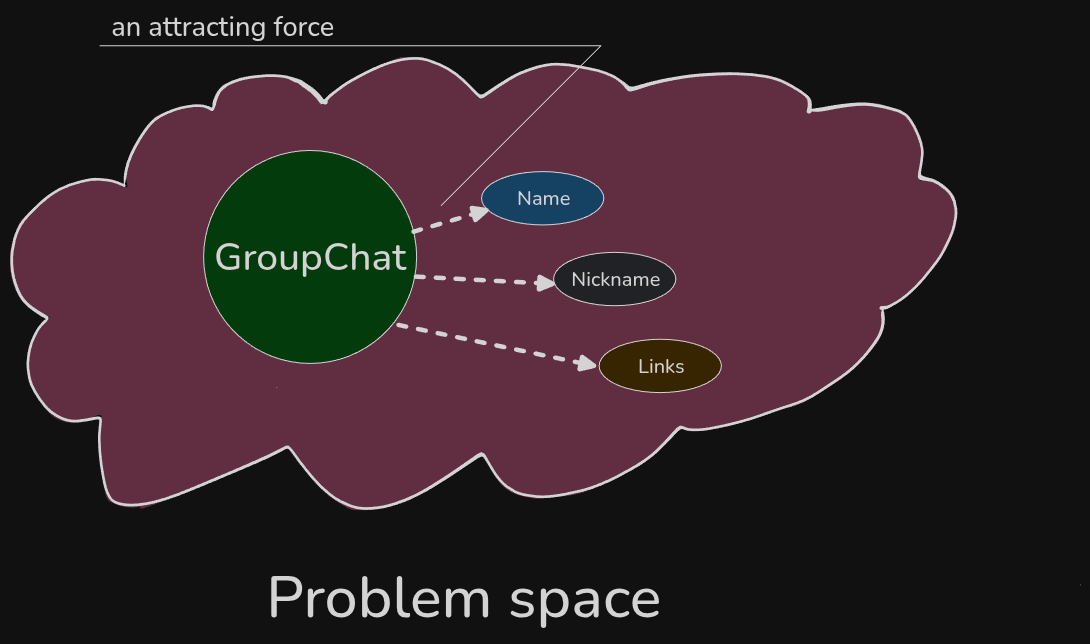
The domain model attracts more concepts, integrating them into itself, hence growing.
As it grows, it attracts even more knowledge, as new appearing concepts are more likely to be conceptually close to this knowledge boundary.
And the cycle continues.
New requirements are coming, and when we take them and think where to "place them", there's a high chance that the most suitable place is within this all-the-time growing boundary.
Then "the structure" becomes complex, messy thing to work with.
And when we add data in the database, baking the structure up, it gets even more complex and knowledge-heavy.
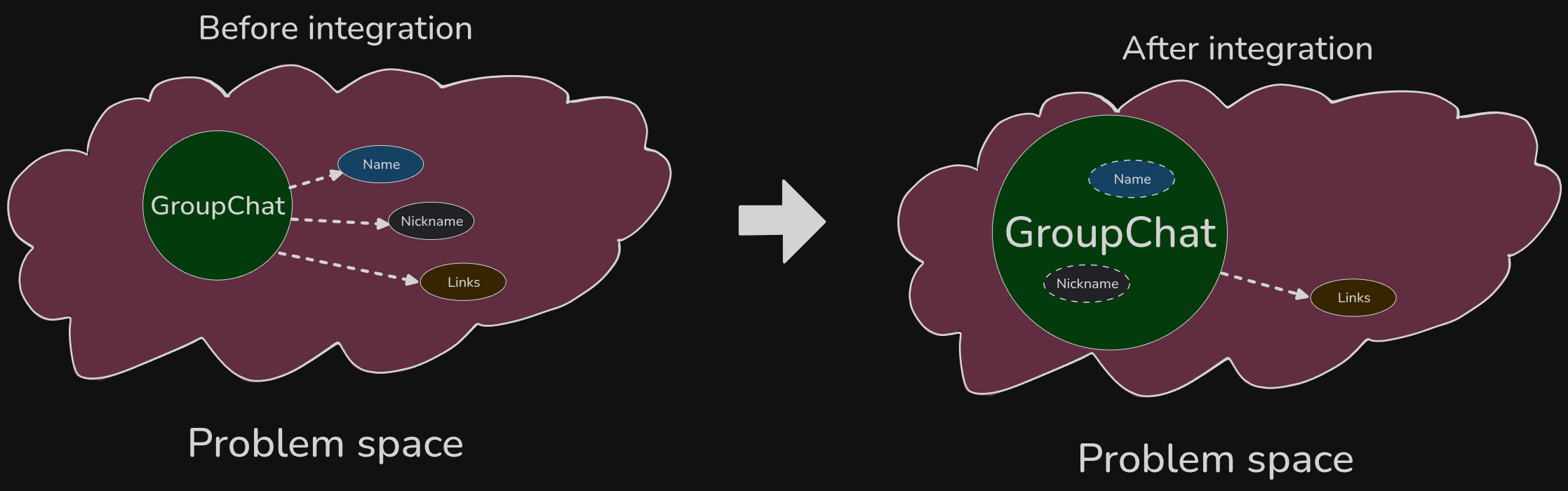
At some point, this little concept that started inside of "a named space", became a "God class" - knowing everything about everything, and being responsible for everything.
There might be more of such concepts, each trying to attract more and more knowledge.
A force?
Might it be that when we express "the knowledge" by naming something, "a knowledge boundary" gets established?
And immediately when it gets established, it starts attracting more and more knowledge?
Let's summon Vlad's formula:
PAIN = f(Strength, Volatility, Distance)
PAIN = Strength x Volatility x Distance
It uses three dimensions, one of which is "(integration) strength", representing the knowledge shared among two concepts.
Let's play and try to think about this "strength" dimension as "a force".
I really like definitions so let's check our match:
strength or energy exerted or brought to bear : cause of motion or change : active power
It seems it makes sense.
We saw that the knowledge boundary (KB) was attracting more concepts (C), trying to close the distance between them.
The closer conceptually they were, the stronger the force was.
We could think about this force as a simple function:
Where:
KBis the knowledge boundary (or a concept)Cis the concept (yet another knowledge boundary?)dis the conceptual difference betweenKBandC(the distance between them)
Of course it's completely made up and not based on any scientific research - just a thought experiment, pure anecdotal concept.
But wait a second, dear Reader.
Isn't it strange?
Maybe there is a force that expresses how particles or celestial bodies attract each other?
Let's bring the formula from Newton's law of universal gravitation:
As our "force" is made up, of course gravity is not an anecdotal, at all.
But could we say that "knowledge" generates gravity-like force?
The knowledge gravity problem
Considering that when we establish knowledge boundaries, "create" named spaces, we might be exposing ourselves to the knowledge gravity problem.
If knowledge boundary is too "big" (capacious), it might be conceptually close to many other concepts (knowledge particles), like we saw in the example with GroupChat.
We could take any other attempt to express the domain model that will be reality-chasing, absolute-based God class - we might end up with a similar phenomenon.
We all know that such "God classes" often follow Noun-based design, the way of thinking that is very common in the industry - "what I hear, I represent".
It might be that all those cautionary tales about "death stars" have more "truth" than we think, as knowledge boundaries might generate gravitational-like force.
Noun-based, contextless and use case agnostic models, like "User", "Product", "Customer", "Tour" (we used that one in the previous tale), will grow and generate even stronger forces.
And it all started with a simple "idea" (a concept), like "let's have a group chat" - and then we "named the space" in a very particular way, hence establishing a knowledge boundary.
We rush to model relationships in the database, which contributes to even "heavier structure".
Bounded planets?
A bounded context is one of the concepts used in the strategic level of Domain-Driven Design.
One could say it's "a conceptual (logical) context that has a model bounded to it".
Can one say that in some sense a bounded context is a "knowledge boundary"?
Hence, each of the contexts could be metaphorically represented as a "planet" in the universe ("the solution space")?
If we take this metaphor, one could conclude that each of those "planets" generates its own gravitational force, supporting or contradicting each other.
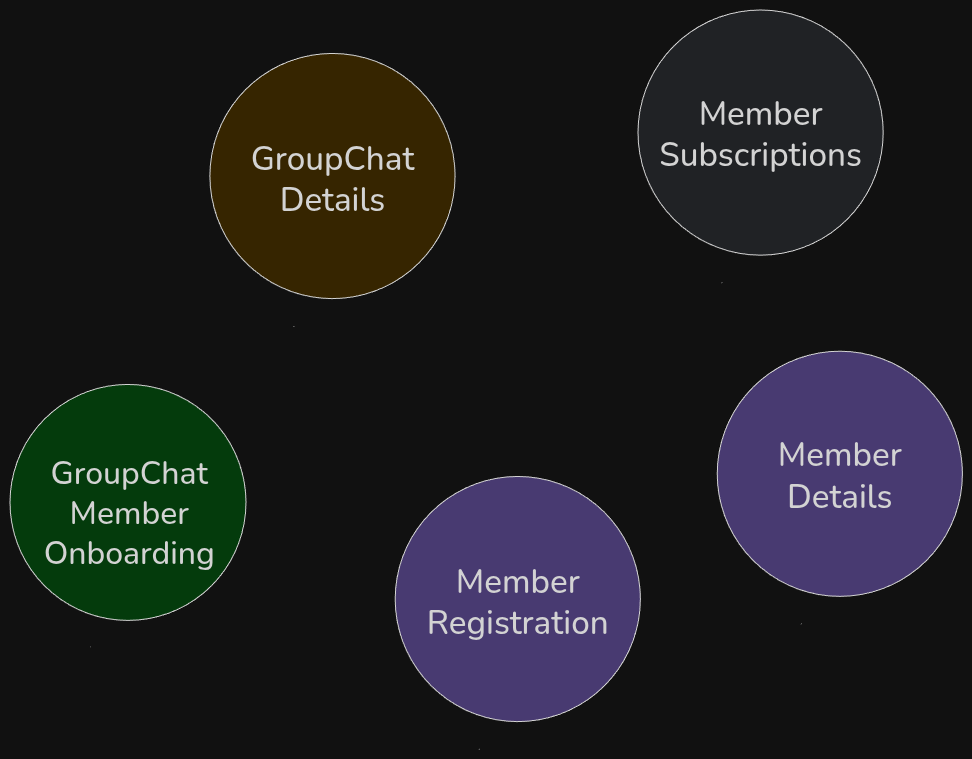
If we take our GroupChat example and try to express boundaries in a slightly different way by applying context segregation principle and using various heuristics (like anti-requirements), we might get different "knowledge boundaries".
One of them could be GroupChatMemberOnboarding, which would be responsible for onboarding members to the GroupChat.
It would have only the knowledge required for running the process of onboarding members.
Of course, The law of eventual composition never stops, and by segregating the contexts in this way, we would need to integrate them back.
But we might get something back, like well-balanced gravity forces, which contribute to dealing with complexity in a different way.
Then, "renaming a group chat" knowledge would belong to a different context - GroupChatDetails - as it typically does not have huge traffic (of course we play with the example, but you get the point, dear Reader).
"The knowledge gravity problem" might be a fractal phenomenon, appearing on various levels of abstraction - functions, components, teams, and organizations - similarly to what we saw in Vlad's book Balancing Coupling.
And (again) one of the conclusions might be:
Boundaries (encapsulation) are one of the most important aspects when designing software
By estabishing them carelessly, we might expose our systems, and ourselves to the problem discussed.
All the big systems should start From concepts to architecture, making sure that there will be no "God knowledge boundary" attracting every concept in the horizon.
Software? Knowledge? Gravity?
"How can you compare physics and software, Damian?", you might ask, dear Reader.
I can't and I don't even try to.
We are playing with ideas and metaphors (and I love them so much!) so that we can change our thinking and perspective and design better systems.
I hope that if next time at least one person thinks that "this concept is too big" or "when I name, I create a knowledge boundary", the world would be a better place.
Even if no one formally examined "knowledge partices", using the magnifying glass or microscope, we can still load certain mental models into our heads to see same things differently.
Tools are interesting and useful, but if the thinking isn't supported by principles and going deeper in understanding why we do things in a certain way, we might become fools.
So next time dear Reader when dealing with a problem or a task, think about the knowledge gravity, and ask yourself:
Why did we name it like this? What do we try to represent now?